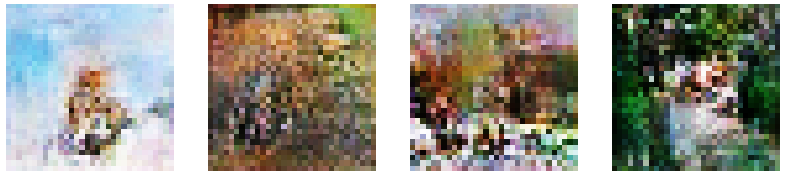
Dessiner des chats avec l'IA
La génération d'images en utilisant l'IA est un sujet extrêmement passionnant, surtout lorsqu'elle s'applique à des chats ! Aujourd'hui, nous allons voir comment utiliser l'intelligence artificielle pour générer de petites images de chats trop mignons 😻.
C'était l'histoire de deux enfants...
... qui rêvaient de travailler dans le monde de la gastronomie. L'un voulait devenir un grand chef cuisinier, et l'autre, un critique culinaire prestigieux. Évidemment, au début, les deux ne connaissaient rien dans ce domaine : le premier ignorait même ce qu'était un plat, et l'autre ne savait pas distinguer un bon d'un mauvais mets. Ainsi, lorsque l'apprenti cuisinier faisait goûter ses plats à son ami, les critiques étaient très aléatoires. Il était incapable de dire si le plat venait de son ami ou d'un vrai grand chef. Au fil du temps, le cuisinier perfectionna sa technique, tandis que le critique apprenait à mieux distinguer ce qui rendait un plat exceptionnel ou banal.
Une histoire de GANs
Les Generative Adversarial Networks (ou Réseaux antagonistes génératifs) sont une architecture utilisée pour la génération de données, notamment pour créer des images. Ce qui rend les GANs redoutablement efficaces, c'est leur capacité à générer des données réalistes à partir d'un bruit aléatoire (appelé vecteur latent). Ce vecteur latent est passé à travers un réseau de neurones convolutifs transposés (pour la génération d'images) avant d'être évalué par un discriminateur. Ce dernier calcule une perte (généralement via une fonction sigmoïde), qui indique au générateur si l'image est "proche" ou "loin" des exemples réels.
Dans l'analogie du cuisinier et du critique gastronomique, l'apprenti cuisinier représente le générateur, qui essaie de créer des plats réalistes, et le critique représente le discriminateur.

Voici ce qu'il se passe pendant l'entrainement:
- Entrainement du discriminateur:
- Le discriminateur est entrainé plusieurs fois avec 80% de vraies images et 20% d'images générées par le générateur
- Les poids du discriminateur sont rétropropagés en fonction de la fonction de coût (entropie croisée dans mon cas)
- Le discriminateur est entrainé plusieurs fois par époque (5 à 10 fois)
- Entrainement du générateur:
- Le générateur produit une image à partir de bruit aléatoire
- Cette image générée est envoyée au discriminateur
- En fonction de la sortie "probabilité vraie image", les gradients sont rétropropagés dans le générateur grâce à une fonction de coût.
- Boucle plusieurs milliers de fois (époques):
- Ce processus est effectué plusieurs milliers de fois (c'est ce qu'on appelle des époques.)
- Ce processus de compétition entre le générateur et le discriminateur est souvent décrit comme un "jeu à somme nulle", où les deux réseaux tentent de se surpasser mutuellement : le générateur essaie de tromper le discriminateur, et le discriminateur essaie de ne pas se faire tromper.
Quelques images générées
Le plus intéressant lorsque l'on expérimente dans ces sujets intéressants, c'est de voir comment notre modèle arrive à représenter au fil du temps une image inédite.
Voici la première itération d'une image générée par le GAN. Évidemment, au début, le vecteur latent est très peu modifié, ce qui explique pourquoi l'image ne ressemble pas encore à un félin mignon.

Au fil du temps, le discriminateur apprend à reconnaître les formes et caractéristiques des chats, ce qui oblige le générateur à produire des images de plus en plus nettes et précises.

Ce résultat est le fruit d'un apprentissage de quatre heures, utilisant des milliers d'images de chats domestiques. Alors, il est vrai que le résultat n'est pas très satisfaisant, mais il y a quelques indices qui montrent que nous sommes sur la bonne voie !

Regardez cette image, on peut clairement identifier des éléments qui caractérise un chat :
- Des pattes semblent apparaîtres en-dessous de la forme brunâtre;
- La forme brunâtre me fait penser à la forme d'un chat, on pourrait même penser voir sa tête au-dessus;
- Le brun / marron utilisé est une couleur possible pour un chat;
- J'ai également l'impression de voir une queue, située à l'arrière du félin.
Je pense que le GAN utilisé pour générer ces chats souffre de la faible qualité des images d'entrainement. En effet, comme nous l'avons vu juste avant, ces images sont redimentionnées en 32x32, ce qui fait perdre pas mal d'informations.
Limitations des GANs
Bien que très puissants, les GANs traditionnels présentent plusieurs limitations :
- Difficultés d'entraînement : ils sont instables, car le générateur ou le discriminateur peut devenir trop puissant, créant un déséquilibre.
- Mode collapse : ils peuvent se concentrer sur une partie limitée de la distribution des données, produisant des échantillons peu variés.
- Consommation de ressources : entraîner un GAN est très coûteux en termes de calcul, surtout pour des images à haute résolution; ce qui nous oblige à redimentionner ces images en faible résolution.
Heureusement, d'autres types de GANs, comme les Wasserstein GANs (WGANs), résolvent certaines de ces limitations. Mais cela fera l'objet d'un autre article !
Créer un GAN
Comme nous l'avons vu précédemment, un GAN repose sur deux sous-modèles entraînés séquentiellement :
- Le discriminateur : un critique qui classe les images en deux catégories : réelles ou générées.
- Le générateur : un modèle qui crée des images à partir d'un vecteur aléatoire.
Et si on mettait les mains dans le cambouis ? Voici un exemple simple de création de ces deux éléments 😁.
Le discriminateur
def build_discriminator():
return models.Sequential([
# 32x32 -> 16x16
layers.Conv2D(16, kernel_size=4, strides=2, padding='same', input_shape=(256, 256, 3)),
layers.LeakyReLU(alpha=0.2),
# 16x16 -> 8x8
layers.Conv2D(32, kernel_size=4, strides=2, padding='same'),
layers.LeakyReLU(alpha=0.2),
# 8x8 -> 4x4
layers.Conv2D(64, kernel_size=4, strides=2, padding='same'),
layers.LeakyReLU(alpha=0.2),
layers.Flatten(),
layers.Dense(1, activation='sigmoid')
])
Explications :
- Les couches
Conv2Dpermettent d'effectuer des convolutions pour détecter différents motifs dans l'image. - Les couches
LeakyReLUajoutent une pente douce aux valeurs négatives, améliorant ainsi la stabilité de l'apprentissage. - La dernière couche
Denseavec une activationsigmoidcalcule la probabilité que l'image soit réelle ou générée.
Le générateur
def build_generator(latent_dim):
layer_input = layers.Input(shape=(latent_dim,))
# Dense et projection initiale
x = layers.Dense(128 * 8 * 8, kernel_initializer="he_normal")(layer_input)
x = layers.ReLU()(x)
x = layers.Reshape((8, 8, 128))(x)
# Upsampling 8x8 -> 16x16
x = layers.UpSampling2D(size=(2, 2))(x)
x = layers.Conv2D(128, kernel_size=3, padding='same')(x)
x = layers.BatchNormalization()(x)
x = layers.ReLU()(x)
# Upsampling 16x16 -> 32x32
x = layers.UpSampling2D(size=(2, 2))(x)
x = layers.Conv2D(128, kernel_size=3, padding='same')(x)
x = layers.BatchNormalization()(x)
x = layers.ReLU()(x)
# Dernière couche pour générer l'image
x = layers.Conv2D(3, kernel_size=3, padding='same', activation='tanh')(x)
return models.Model(inputs=layer_input, outputs=x)
Explications :
-
Préparation de la structure :
- Le vecteur latent (bruit aléatoire) est projeté dans un espace tridimensionnel (8x8x128).
Reshapeorganise la sortie en une image partielle.
-
Upsampling :
- Cette technique double la résolution de l'image à chaque étape.
- Les couches de convolution ajoutent des détails à l'image sans modifier sa taille.
-
Génération de l'image finale :
- La couche finale produit une image 32x32x3 (RGB) avec des valeurs normalisées entre -1 et 1 (grâce à
tanh).
- La couche finale produit une image 32x32x3 (RGB) avec des valeurs normalisées entre -1 et 1 (grâce à
Conclusion
Les GANs ont révolutionnés la génération d'images dans le monde de l'IA. Ils sont très performants pour générer un certain type d'image précis. Néanmoins, ils sont assez compliqué à entraîner pour avoir de vrais bon résultats satisfaisants. Depuis quelques années, une version améliorée des GANs (WGANs) permettent d'améliorer significativement les résultats des images générées.
Il est important de noter également que le modèle Dall-E (développé par OpenAI), n'utilise probablement pas de GAN pour générer des images, ceci fera l'objet d'un autre article !